Aperçu¶
Jupyter: Expérience conviviale de R et Python¶
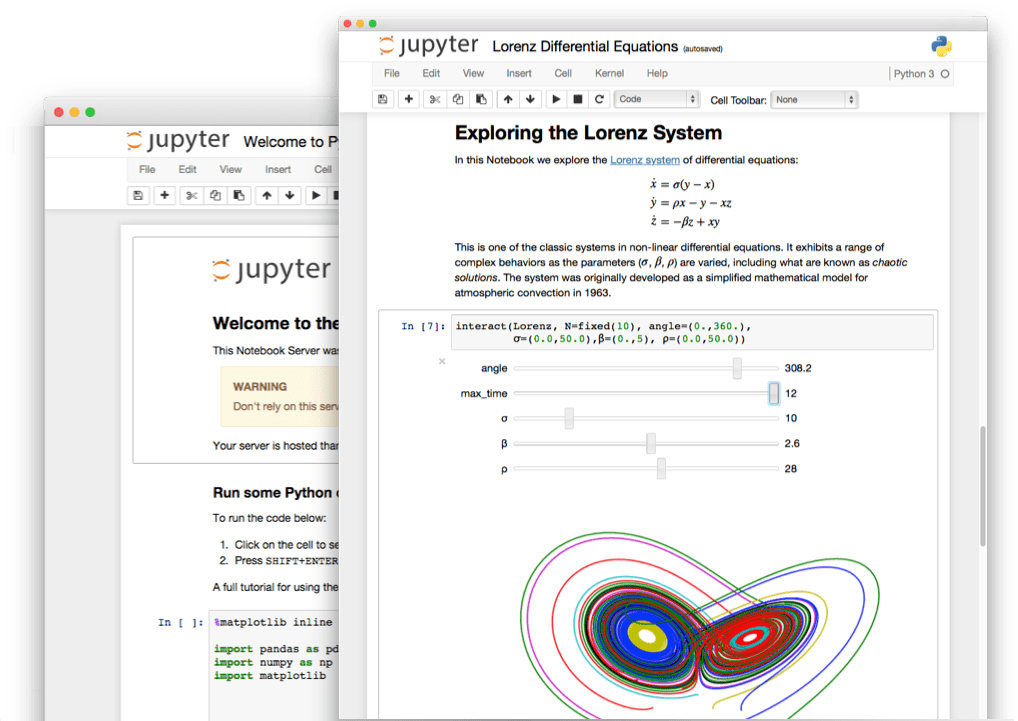
Jupyter vous propose des bloc-notes pour écrire votre code et réaliser des visualisations. Vous pouvez rapidement itérer, visualiser et partager vos analyses. Parce qu'il fonctionne sur un serveur (que vous avez configuré dans la section Kubeflow), vous pouvez effectuer de très grandes analyses sur du matériel centralisé, en ajoutant autant de puissance que nécessaire! Et comme il est sur le nuage, vous pouvez également le partager avec vos collègues.
Explorez vos données¶
Jupyter offre un certain nombre de fonctionnalités (et nous pouvons en ajouter d'autres)
- Éléments visuels intégrés dans votre bloc-notes
- Volume de données pour le stockage de vos données
- Possibilité de partager votre espace de travail avec vos collègues
Explorez vos données avec une API¶

Utilisez Datasette , une interface de programmation (API) JSON instantanée pour vos bases de données SQLite. Exécutez des requêtes SQL de manière plus interactive !
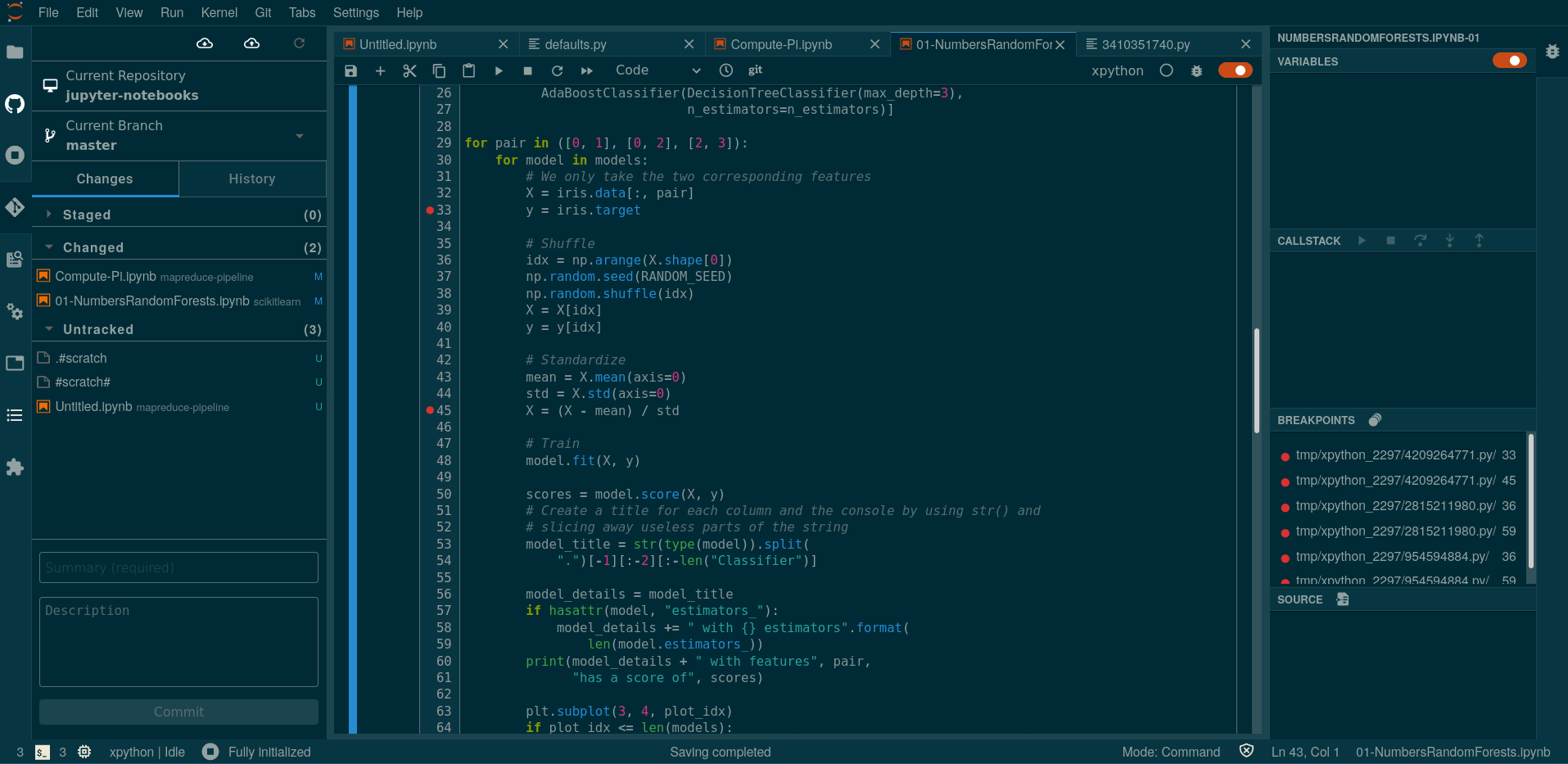
Environnement de développement dans le navigateur¶
Créez pour explorer, et aussi pour écrire du code
- Linting et débogage
- Intégration Git
- Terminal intégré
- Thème clair/foncé (changer les paramètres en haut)
Plus de renseignements sur Jupyter ici
Installation¶
Commencez avec les exemples¶
Lorsque vous avez démarré votre serveur, il a été chargé de modèles de
bloc-notes. Parmi les bons blocs-notes pour commencer, il y a
R/01-R-Notebook-Demo.ipynb et ceux dans scikitlearn. Les bloc-notes
pytorch et tensorflow sont excellents si vous connaissez l'apprentissage
automatique. mapreduce-pipeline et ai-pipeline sont plus avancés.
Certains bloc-notes ne fonctionnent que dans certaines versions de serveur
Par exemple, gdal ne fonctionne que dans l'image géomatique. Donc, si vous
utilisez une autre image, un bloc-notes utilisant gdal pourrait ne pas
fonctionner.
Ajout de logiciels¶
Vous n'avez pas sudo dans Jupyter, mais vous pouvez utiliser
ou
N'oubliez pas de redémarrer votre noyau Jupyter par la suite, pour accéder à de nouvelles trousses.
Assurez-vous de redémarrer le noyau Jupyter après l'installation d'un nouveau logiciel
Si vous installez un logiciel dans un terminal, mais que votre noyau Jupyter était déjà en cours d'exécution, il ne sera pas mis à jour.
Y a-t-il quelque chose que vous ne pouvez pas installer?
Si vous avez besoin d'installer quelque chose, communiquez avec nous ou ouvrir une question GitHub. Nous pouvons l'ajouter au logiciel par défaut.
Une fois que vous avez les bases ...¶
Entrer et sortir des données de Jupyter¶
Vous pouvez télécharger et charger des données vers ou depuis JupyterHub directement dans le menu. Il y a un bouton de chargement en haut, et vous pouvez cliquer avec le bouton droit de la souris sur la plupart des fichiers ou dossiers pour les télécharger.
Stockage partagé en compartiment¶
Il existe également un dossier buckets monté dans votre répertoire personnel, qui contient les fichiers dans Stockage Blob Azure.
Reportez-vous à la section Stockage pour plus de détails.
L'analyse des données¶
L'analyse des données est un art sous-estimé.
L'analyse des données est le processus d'examen et d'interprétation de grandes quantités de données pour extraire des informations utiles et tirer des conclusions significatives. Cela peut être fait à l'aide de diverses techniques et outils, tels que l'analyse statistique, l'apprentissage automatique et la visualisation. L'objectif de l'analyse des données est de découvrir des modèles, des tendances et des relations dans les données, qui peuvent ensuite être utilisés pour éclairer les décisions et résoudre les problèmes. L'analyse de données est utilisée dans un large éventail de domaines, des affaires et de la finance aux soins de santé et à la science, pour aider les organisations à prendre des décisions plus éclairées sur la base de preuves et d'informations basées sur des données.
JupyterLab¶
Traiter les données à l'aide de R, Python ou Julia dans JupyterLab

Le traitement des données à l'aide de R, Python ou Julia est simplifié grâce à l'espace de travail d'analyse avancée. Que vous débutiez dans l'analyse de données ou que vous soyez un data scientist expérimenté, notre plateforme prend en charge une gamme de langages de programmation pour répondre à vos besoins. Vous pouvez installer et exécuter des packages pour R ou Python pour effectuer des tâches de traitement de données telles que le nettoyage, la transformation et la modélisation des données. Si vous préférez Julia, notre plateforme offre également un support pour ce langage de programmation.