SweetViz: rationaliser l'EDA avec des visualisations élégantes¶
SweetViz, une bibliothèque Python open source, simplifie le processus d'analyse exploratoire des données (EDA) avec seulement deux lignes de code, générant des visualisations époustouflantes et haute densité. Le résultat est une application HTML entièrement autonome, ce qui en fait un outil pratique pour un aperçu rapide des caractéristiques des données et des comparaisons entre les ensembles de données.
Principales caractéristiques:¶
- Analyse cible: Visualisez comment une valeur cible (par exemple, « Survécu » dans l'ensemble de données Titanic) est en corrélation avec d'autres caractéristiques, ce qui facilite la compréhension des caractéristiques de la cible.
- Visualisez et comparez: Comparez sans effort des ensembles de données distincts, tels que les données d'entraînement et de test, et explorez les caractéristiques intra-ensemble (par exemple, homme contre femme).
- Associations de types mixtes: SweetViz intègre de manière transparente des associations pour les types de données numériques (corrélation de Pearson), catégorielles (coefficient d'incertitude) et catégorielles-numériques (rapport de corrélation), fournissant des informations complètes pour divers types de données.
- Inférence de type: Détecte automatiquement les fonctionnalités numériques, catégorielles et textuelles, avec la possibilité de remplacements manuels si nécessaire.
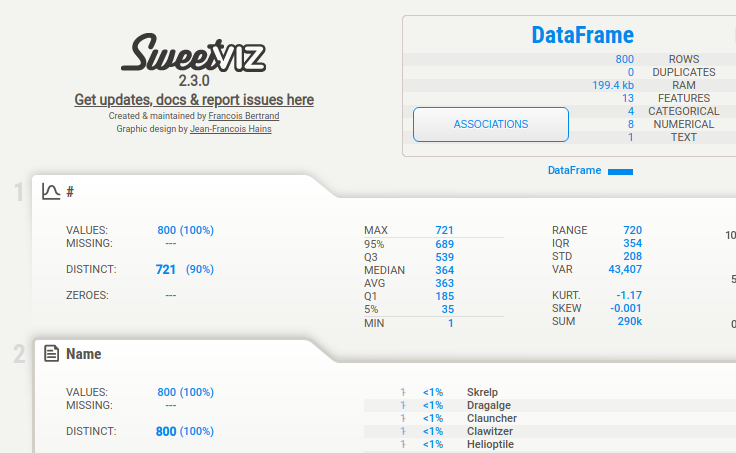
- Informations récapitulatives: Obtenez des informations sur le type, les valeurs uniques, les valeurs manquantes, les lignes en double et les valeurs les plus fréquentes dans l'ensemble de données.
- Analyse numérique: Explorez les fonctionnalités numériques avec des statistiques telles que min/max/plage, quartiles, moyenne, mode, écart type, somme, écart absolu médian, coefficient de variation, aplatissement et asymétrie.
Installation:¶
Pour démarrer avec SweetViz, installez la bibliothèque ainsi que les autres dépendances nécessaires à l'aide de la commande suivante:
%%capture
! pip install -U sweetviz ydata-profiling
Exemple de base:¶
Effectuer une EDA de base avec SweetViz ne nécessite que deux lignes de code. Dans l'exemple ci-dessous, nous analysons un ensemble de données Pokémon et générons un rapport détaillé:
import sweetviz as sv
import pandas as pd
from ydata_profiling.utils.cache import cache_file
file_name = cache_file(
"pokemon.csv",
"https://raw.githubusercontent.com/bryanpaget/html/main/pokemon.csv"
)
pokemon_df = pd.read_csv(file_name)
my_report = sv.analyze(pokemon_df)
my_report.show_notebook()
| …
Comparaison de deux dataframes:¶
SweetViz étend ses capacités pour comparer deux ensembles de données, tels que des ensembles de formation et de test. Dans cet exemple plus complexe, nous examinons les différences dans la fonctionnalité « Attaque »:
from sklearn.model_selection import train_test_split
X = pokemon_df[['Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed']]
y = pokemon_df[['Type 1', 'Type 2']]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
train_df = X_train
test_df = X_test
comparison_report = sv.compare(train_df, test_df, target_feat='Attack')
comparison_report.show_notebook()
Renforcez votre parcours d'exploration de données avec SweetViz, en créant des rapports visuellement attrayants et informatifs avec un minimum d'effort. Que vous soyez un data scientist, un étudiant ou un chercheur, SweetViz propose une approche conviviale pour obtenir un aperçu rapide de vos ensembles de données.