Argo
Flux de travail Argo¶

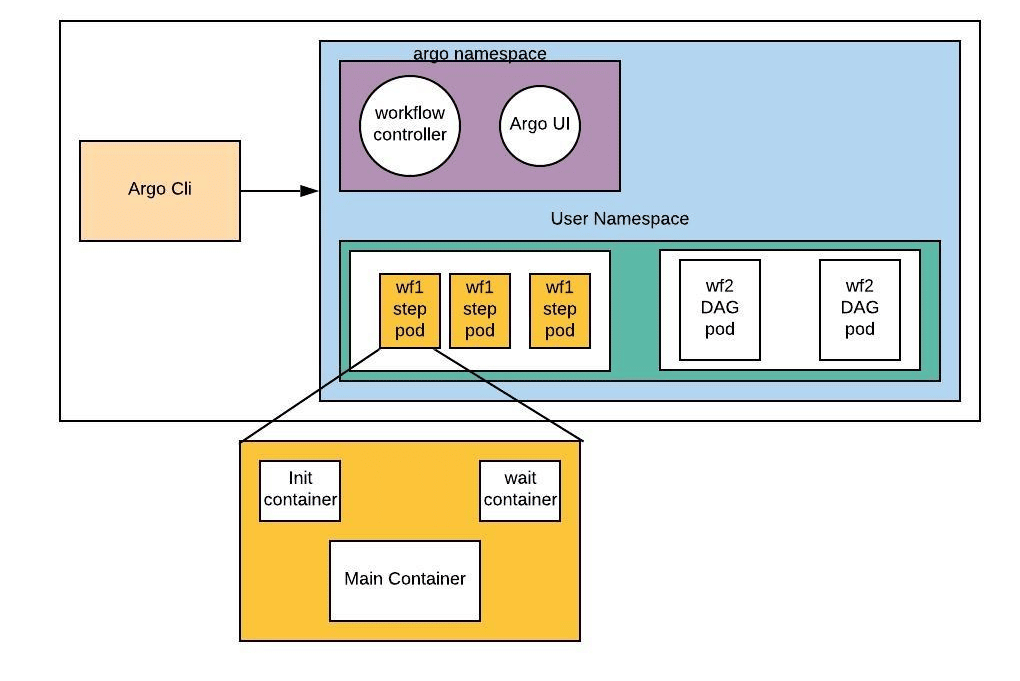
Flux de travail Argo est un moteur de flux de travail à logiciel libre natif de conteneur pour orchestrer des tâches parallèles sur Kubernetes. Les flux de travails Argo sont implémentés en tant que Kubernetes CRD (Custom Resource Definition). Il est particulièrement adapté aux flux de travail de science des données et aux flux de travail d’apprentissage automatique.
La documentation complète peut être trouvée ici.
Les flux de travails Argo ont les avantages suivants:
- Les tâches des flux de travail peuvent être définies sous forme de scripts (ex. Python) ou être conteneurisées (ex. Docker).
- Des flux de travail complexes peuvent être modélisés à l'aide de graphes acycliques dirigés (DAG) pour capturer les chaînes de dépendance.
- Les tâches indépendantes peuvent être exécutées en parallèle avec une granularité jusqu'au niveau de mise en œuvre, réduisant ainsi les charges de tâches chronophages.
- Agnositique de la plateforme Kubernetes, ce qui signifie que votre travail est très portable.
Avec les flux de travails Argo, vous pouvez facilement créer des flux de travails qui intègrent des tâches telles que des constructions et des déploiements automatisés, le prétraitement des données, la formation de modèles et le déploiement de modèles, le tout dans un environnement Cloud Native Kubernetes.
Flux de travail Argo
Vous trouverez ci-dessous un exemple de cas d'utilisation de flux de travail Argo, dans lequel nous formons un modèle d'apprentissage automatique à l'aide des flux de travail Argo sur AAW.
1. Écrivez un script pour entraîner votre modèle¶
Voici un exemple de script qui entraîne un modèle de régression logistique sur l'ensemble de données iris. N'oubliez pas de consulter le code de chaque langue ci-dessous.
2. Écrivez un Dockerfile pour exécuter votre code¶
Vous aurez besoin d'un Dockerfile qui inclut toutes les dépendances nécessaires pour entraîner votre modèle d'apprentissage automatique. Cela pourrait inclure:
- des paquets comme
scikit-learn,pandasounumpysi vous utilisezPythoncaret,janitorettidyversesi vous utilisezR
- vos propres bibliothèques ou scripts personnalisés
- le code de votre modèle d'apprentissage automatique sous la forme d'un script comme dans l'exemple ci-dessus.
Utilisez le Dockerfile suivant comme point de départ pour vos projets R et Python.
| Dockerfile | |
|---|---|
3. Écrivez votre flux de travail en YAML¶
YAML est encore un autre langage de balisage et vous devrez écrire les étapes de votre pipeline de formation dans un fichier YAML de flux de travails Argo. Ce fichier doit inclure une référence au Dockerfile que vous avez créé à l'Étape 1, ainsi que toutes les données d'entrée et de sortie avec lesquelles vous travaillerez.
Voici un exemple de fichier YAML pour un pipeline d'apprentissage automatique simple qui entraîne un modèle de régression logistique sur l'ensemble de données iris. La seule vraie différence entre les versions Python et R est la commande command: ["python", "train.py"] vs command: ["Rscript", "train.R"] et le les modèles sont stockés dans différents formats, pkl pour python et rds pour R.
Le fichier YAML définit une seule étape appelée train qui exécute un script appelé train.py ou train.R dans l'image Docker machine-learning:v1. Le script prend un fichier d'ensemble de données d'entrée, spécifié par un paramètre appelé dataset, et génère un fichier de modèle entraîné vers un artefact de sortie appelé model.pkl ou model.rds selon le langage utilisé.
4. Soumettez le flux de travail à l'aide de l'entrée de ligne de commande(CLI) du flux de travail Argo¶
Pour exécuter le flux de travail ci-dessus, vous devrez d'abord envoyer le Dockerfile vers notre registre de conteneurs, puis soumettre le fichier YAML à l'aide de la commande argo submit. Une fois le pipeline terminé, vous pouvez récupérer le fichier de modèle entraîné en téléchargeant l'artefact de sortie à partir de la commande argo logs.
Il est également possible de soumettre des flux de travail argo à partir des flux de travail à l'aide de SDK et d'appels API (c'est juste un autre service Web !). Voir cette section.
5. Surveillez le pipeline à l'aide de la CLI du flux de travail Argo¶
Pendant l'exécution du pipeline, vous pouvez surveiller sa progression à l'aide de la CLI de flux de travail Argo. Cela vous montrera quelles étapes se sont terminées avec succès et lesquelles sont toujours en cours. Vous trouverez ci-dessous quelques commandes utiles. Pour plus d'informations sur la CLI des flux de travail Argo, veuillez consulter la documentation officielle de la CLI de flux de travail Argo .
$ argo list # lister les flux de travail actuels
$ argo get workflow-xxx # obtenir des informations sur un flux de travail spécifique
$ argo logs workflow-xxx # imprimer les journaux d'un flux de travail
$ argo delete workflow-xxx # suprimer un flux de travail
6. Récupérer le modèle entraîné¶
Une fois le pipeline terminé, vous pouvez récupérer les données de sortie à l'aide de la commande argo logs ou en affichant les artefacts de sortie à l'aide de la CLI, c'est-à-dire accéder au répertoire que vous avez spécifié dans votre script et localiser le fichier model.pkl ou model.rds. L'extrait de code suivant, extrait du script de formation ci-dessus, indique au langage de programmation respectif où enregistrer le modèle entraîné.
Exemples utilisant des SDK basés sur flux de travail Argo¶
Argo prend en charge les bibliothèques client, générées automatiquement et gérées par la communauté, qui incluent les SDK Java et Python.
Si vous préférez utiliser un cadres de niveau supérieur, alors Couler et Hera sont des alternatives bien adaptées. Ces cadress rendent la création et la gestion de flux de travail complexes plus accessibles à un public plus large.
Hera¶
Hera vise à simplifier le processus de création et de soumission de flux de travail en éliminant de nombreux détails techniques via une interface de programmation d'application simple. Il utilise également un ensemble cohérent de terminologie et de concepts qui s'alignent sur les flux de travail Argo, permettant aux utilisateurs d'apprendre et d'utiliser plus facilement les deux outils ensemble.
Couler¶
Couler fournit une interface de programmation d'applications simple et unifiée pour définir des flux de travail à l'aide d'un style de programmation impératif. Il construit également automatiquement des graphiques acycliques dirigés (DAG) pour les flux de travail, ce qui peut contribuer à simplifier le processus de création et de gestion de ceux-ci.
Ressources supplémentaires pour les flux de travail Argo¶
Des exemples de flux de travail Argo peuvent être trouvés dans les référentiels Github suivants :