Argo
Argo Workflows¶

Argo Workflows is an open source container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo Workflows is implemented as a Kubernetes CRD (Custom Resource Definition). It is particularly well-suited for use in data science workflows and machine learning workflows.
Full documentation can be found here.
Argo Workflows have these advantages:
- Workflow tasks can be defined as scripts (ex. python) or be containerized (ex. docker).
- Complex workflows can be modeled using Directed Acyclic graphs (DAGs) to capture dependency chains.
- Independent tasks can be run in parallel with granularity to the level of implementation, reducing time intensive task loads.
- Kubernetes platform agnositic, which means that your work is very portable.
With Argo Workflows, you can easily build workflows that incorporate tasks such as automated builds and deployments, data preprocessing, model training, and model deployment, all within a Cloud Native Kubernetes environment.
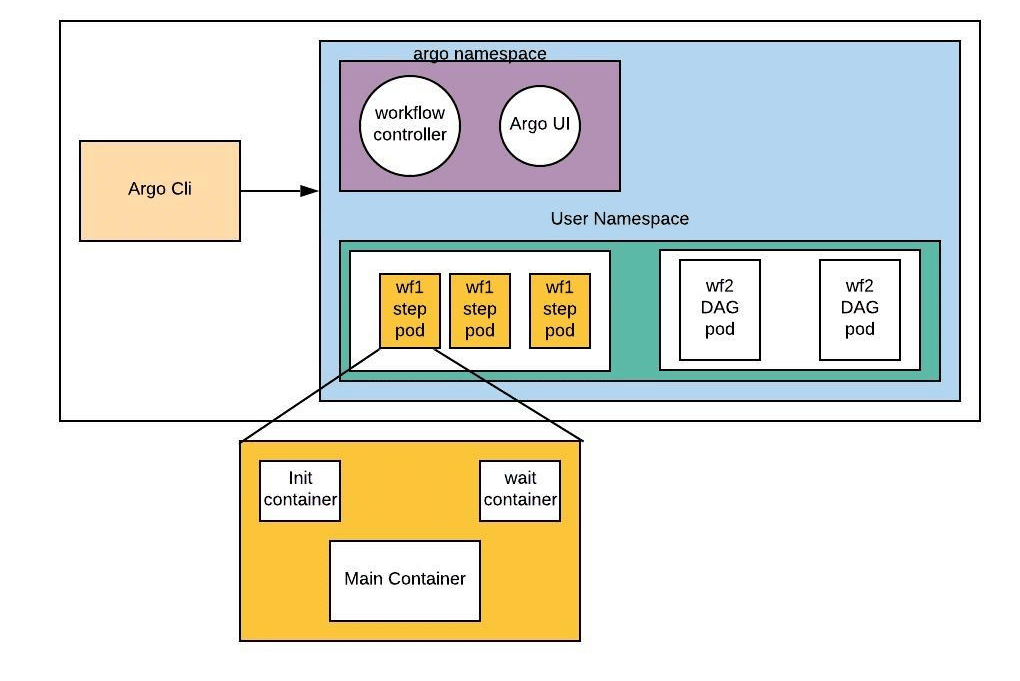
Argo Workflows
Below is an example use-case of Argo Workflows, where we train a machine learning model using Argo Workflows on the AAW.
1. Write a script to train your model¶
Here's an example script that trains a logistic regression model on the iris dataset. Don't forget to view the code from each language below.
2. Write a Dockerfile to run your code¶
You'll need a Dockerfile that includes all necessary dependencies for training your machine learning model. This could include
- packages like
scikit-learn,pandasornumpyif you are usingPythoncaret,janitorandtidyverseif you are usingR
- your own custom libraries or scripts
- your machine learning model code in the form of a script as in the above example.
Use the following Dockerfile as a starting point for your R and Python projects.
3. Write your workflow in YAML¶
YAML is Yet Another Markup Language and you'll need to write down the steps of your training pipeline in an Argo Workflows YAML file. This file should include reference to the Dockerfile you created in Step 2, as well as any input data and output data you'll be working with.
Here is an example YAML file for a simple machine learning pipeline that trains a logistic regression model on the iris dataset. The only real difference between the Python and R versions is the command command: ["python", "train.py"] vs command: ["Rscript", "train.R"] and the models are stored in different formats, pkl for python and rds for R.
The YAML file defines a single step called train that runs a script called train.py or train.R in the Docker image machine-learning:v1. The script takes an input dataset file, specified by a parameter called dataset, and outputs a trained model file to an output artifact called model.pkl or model.rds depending on the language used.
4. Submit the workflow using the Argo Workflows CLI¶
To run the above workflow, you will first need to push the Dockerfile to our container registry and then submit the YAML file using the argo submit command. Once the pipeline has completed, you can retrieve the trained model file by downloading the output artifact from the argo logs command.
It's also possible to submit argo workflows from within workflows using SDKs and API calls (it's just another web-service!). See this section.
5. Monitor the pipeline using the Argo Workflows CLI¶
As the pipeline runs, you can monitor its progress using the Argo Workflows CLI. This will show you which steps have completed successfully and which are still running. Below are some useful commands, for more information about the Argo Workflows CLI, please check out the official Argo Workflows CLI documentation.
$ argo list # list current workflows
$ argo get workflow-xxx # get info about a specific workflow
$ argo logs workflow-xxx # print the logs from a workflow
$ argo delete workflow-xxx # delete workflow
6. Retrieve the trained model¶
Once the pipeline has completed, you can retrieve the output data using the argo logs command or by viewing the output artifacts using the CLI, i.e. navigate to the directory you specified in your script and locate the file model.pkl or model.rds. The following code snippet, taken from the above training script, tells the respective programming language where to save the trained model.
Examples using Argo Workflows-based SDKs¶
Argo supports both auto-generated and community maintained client libraries, which includes Java and Python SDKs.
If you prefer to use a higher level framework, then Couler and Hera are well-suited alternatives. These frameworks make the creation and management of complex workflows more accessible to a wider audience.
Hera¶
Hera aims to simplify the process of building and submitting workflows by abstracting away many of the technical details through a simple application programming interface. It also uses a consistent set of terminology and concepts that align with Argo Workflows, making it easier for users to learn and use both tools together.
Couler¶
Couler provides a simple, unified application programming interface for defining workflows using an imperative programming style. It also automatically constructs directed acyclic graphs (DAGs) for the workflows, which can help to simplify the process of creating and managing them.
Additional Resources for Argo Workflows¶
Example Argo Workflows workflows can be found in the following Github repositories: